QuickFITS 下载突破 20000
过年时正好又要面试,想着整理一下之前的项目用来讲故事。想着能不能查到 Github Release 的下载量,简单一搜还真能查到。激动的心颤抖的手,在把我的 repo 地址输进去后,工具显示 Windows 版的插件已经有了超过 2万的下载。而且最新版本上线不到一个月,在没有任何更新推送渠道的情况下又有了快 300 下载。这着实让我高兴了好几天。
这篇文章主要分享我在开发 QuickFITS 过程中遇到的一些有趣的挑战。最初,我认为 FITS 文件格式非常复杂,找到用于 C++ 的第三方库 CCfits 后我又觉得它不过就是把原始数据像 BMP 一样放到了文件容器里再加个文件头罢了。直到最近遇到一些反馈,我才开始重新关注具体的实现细节,发现这个格式还是有许多需要隐形的坑的。

文件头 Header
Keywords
首先,FITS Keywords 的标准并不统一,规范中强制要求的 Keywords 实际上非常少,而且它们中并没有太多对摄影有用的信息。例如,用于记录拍摄参数的 Header,类似于摄影中的 Exif 信息,不同的公司有不同的标准。以 ZWO 的 ASI 系列软件为例,用于记录曝光时间的 Keywords 就有好几个。例如,拍摄行星时使用的是微秒,而长时间曝光则使用秒,这两者使用的是完全不同的Keywords。其它软件也有别的标准。这对于预览显示造成了一些影响,除非我手动去匹配这些 Keywords,否则它们无法正确显示。
文件头不是个字典
由于历史原因,FITS 的文件存储存在许多限制。例如,它的文件头分为三块,其中keyword部分最多只能包含8个字符,这意味着你不能使用自然语言完整单词来命名。整条 header 包括 comment 评论区域的字符数也被限制在80个字符以内。如果需要更长的空间,就必须使用多个 card,我严重怀疑 card 的概念是来自于物理上的打孔纸带。大多数的 header 内容可以在这个限制内被记录,但是有两个特殊 keyword,COMMENT 和 HISTORY,在大多数时候都会远远超过 80 个字符的限制。所以又有了CONTINUE keyword / card 的概念。这个机制可以让多个 card 被最终映射到一条内容上,这也意味着 card 和 keyword 并不会一一对应,不能用字典表示。
为了实现按添加顺序显示文件头,我本来想完全替换掉 CCFits 的文件头读取代码,直接使用 cfitsio 读取源数据。但遇上了这个坑加上数据类型也要自己处理,最终还是保留了对 CCFits 的依赖。
Row Order
Row Order 描述了文件中数据排列的顺序 —- 从底向上 BOTTOM-UP 还是从上向下 TOP-DOWN。前者是数学中常用的,认为图像的原点在左下角,坐标系统是直角坐标系;后者是图形学中标准,从屏幕的角度出发,认为屏幕的左上角是原点。现在大多数拍摄软件会用 TOP-DOWN 的顺序存储数据,并在文件头中记录这一操作。但有些拍摄软件并不包含这一 header,所以后期软件要自行决定默认的顺序。另外对于黑白图片来说,两种顺序只是竖直翻转的关系,但对于 bayer 状态下的彩色数据,bayer 阵列是不是也要被翻转呢?这就引发了下一个问题。
Bayer 阵列
我在网上找到了一个拜尔阵列的测试图,大概来自于 ASTAP 的作者 hnsky。虽然拜尔阵列只有四种基本类型(特殊的 294 Quad bayer 还没有测试过),但结合另外两个关键词,会产生许多变化。一个是上面说到的 row order,另一个是比较少见的 x offset 和 y offset,我对它们的具体作用不是很清楚。主要的问题是,这个测试图只提供了原始的 FITS 文件,并没有提供一个ground truth。更糟糕的是当我用不同的现有软件打开这些测试图时,发现它们显示的结果也都不同。所以我只能根据自己的理解处理这两个关键词了。
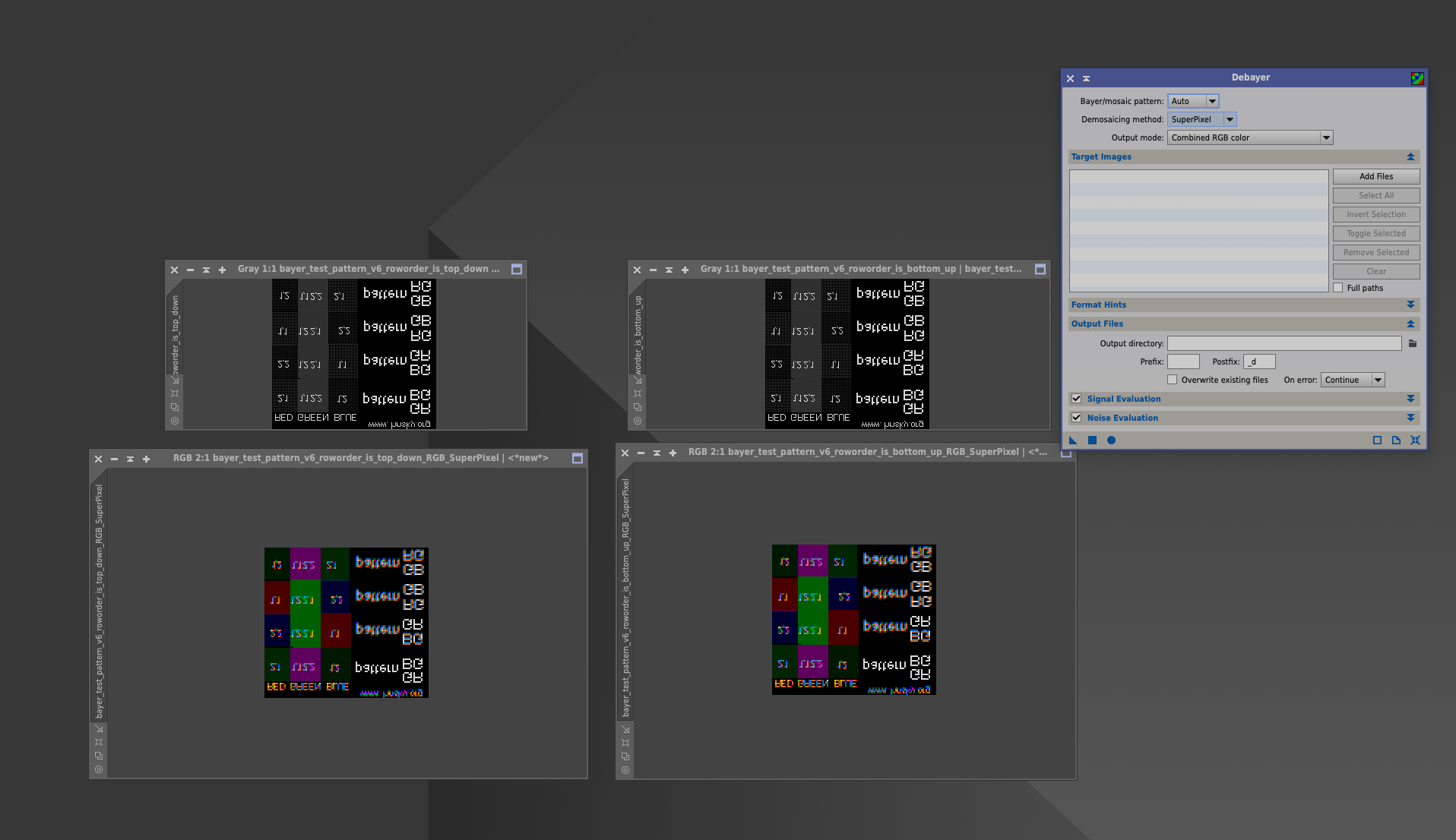 Pixinsight
Pixinsight
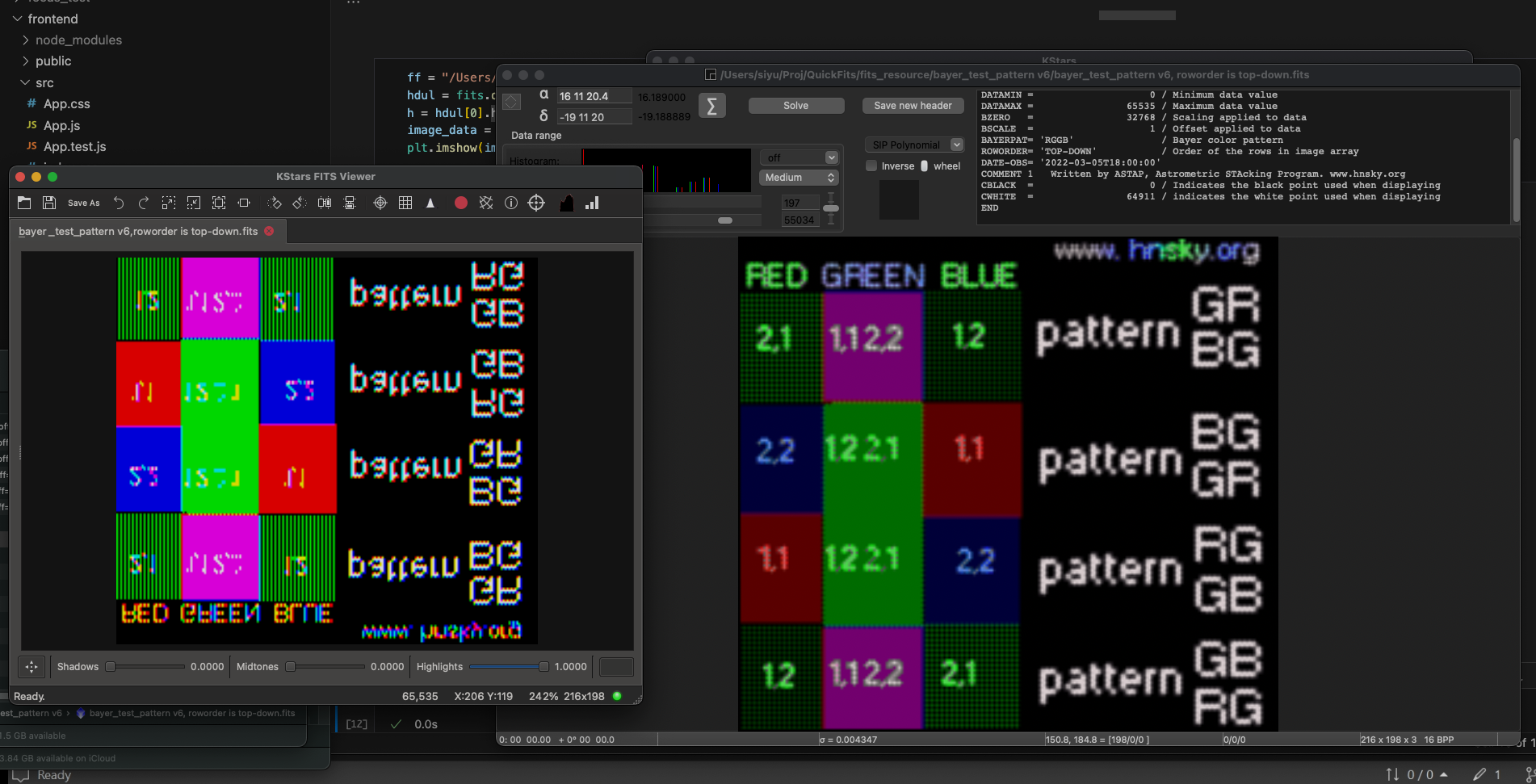 Kstars vs ASTAP TOP-DOWN
Kstars vs ASTAP TOP-DOWN
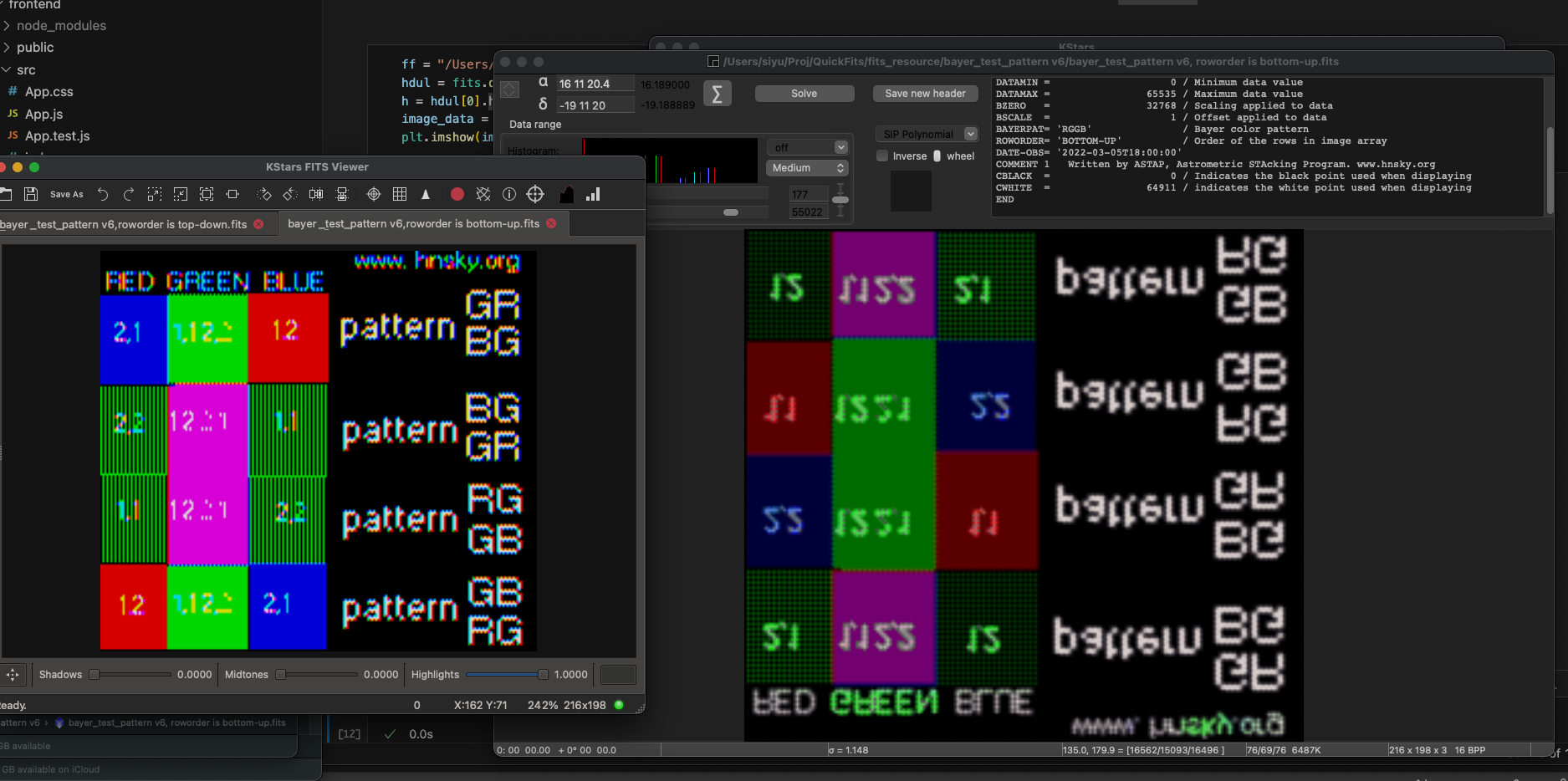 Kstars vs ASTAP BOTTOM-UP
Kstars vs ASTAP BOTTOM-UP