用Python打开嫦娥玉兔的科学数据

这是我的B站视频的文字稿
上一周,我在宇宙驿站公布了嫦娥4号任务全景相机和地貌相机科学数据的熟肉。微博上随口问了一句有没有对熟肉的制作过程感兴趣,没想到还真的有人。所以在这里我就讲一讲科学数据是怎么变成图片的。
(做过天文后期的同学一定会觉得下面的很多名词和概念很亲切,如果你没做过也没关系,我会尽量说的通俗一点。)
原始数据怎么下载我就不说了,下来之后得到一堆双击根本打不开的文件。他们的后缀有两种:2BL和2B。
2BL文件都很小 ,拿记事本可以打开。里面记录了拍摄器材、拍摄时间和曝光参数等信息,最重要的是它存储了一个文件路径,也就是同名的2B文件。2B文件里面才是实际的图片数据。这种数据的组织形式就叫做PDS,是NASA开发的一种专门用于存储行星探索任务的数据系统。
(都是为了存个文件头,fits他不香吗)
所以我们的目标很简单,
读PDS文件,提取出图像数据,保存。
本着不重造轮子的原则,简单搜索一下,有个叫 PDS4 tools 的库刚好可以完成这个任务。
对于TCAM来说,整个转化过程就是调库读图,再调用另一个库存图,没有任何花里胡哨的操作。
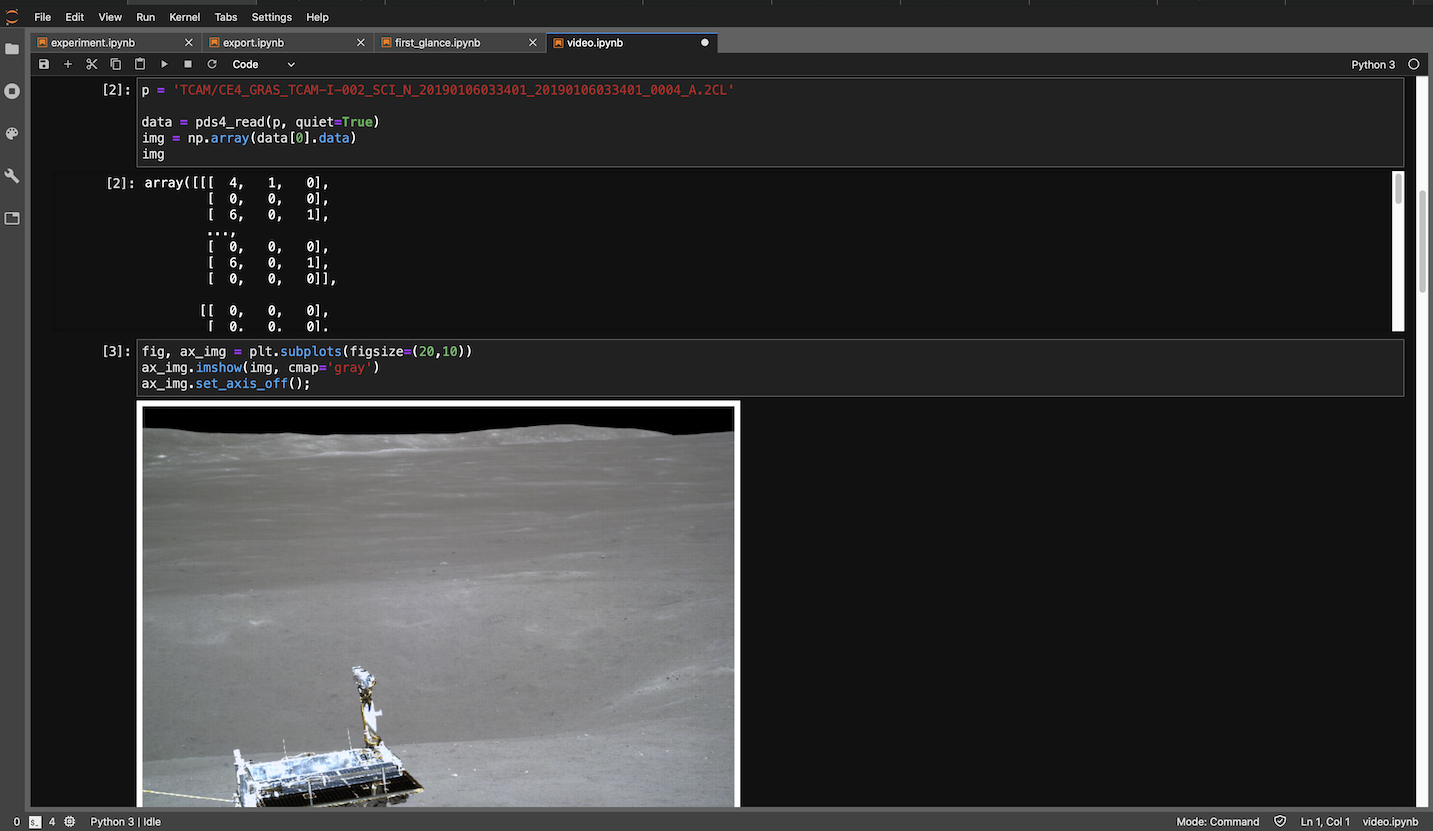 TCAM的读取
TCAM的读取
至于全景相机的彩色图像,我们得到的其实是原始的马赛克灰度图像。
 PCAM读到的是马赛克灰度图像
PCAM读到的是马赛克灰度图像
这里我先科普一下相机到底是怎么拍出彩色图片的。由于相机中的感光元件是色盲,他们只对亮度敏感而不能分辨颜色。为了获得颜色信息,工程师们在感光元件前加了一层滤镜。这个滤镜上马赛克状排布着许许多多红绿蓝三种颜色的小滤镜,每个滤镜只允许三原色中的一种透过,所以我们可以知道打在滤镜背后像素上的光的颜色,也就可以使用算法从只代表亮度的灰度图像还原出色彩。这种滤镜排布在1976年被柯达公司的bayer先生提出,是现在使用的最广的色彩滤镜阵列,所以包含彩色信息的灰度图像常被成为bayer图像,对应的还原色彩的过程也叫做debayer。
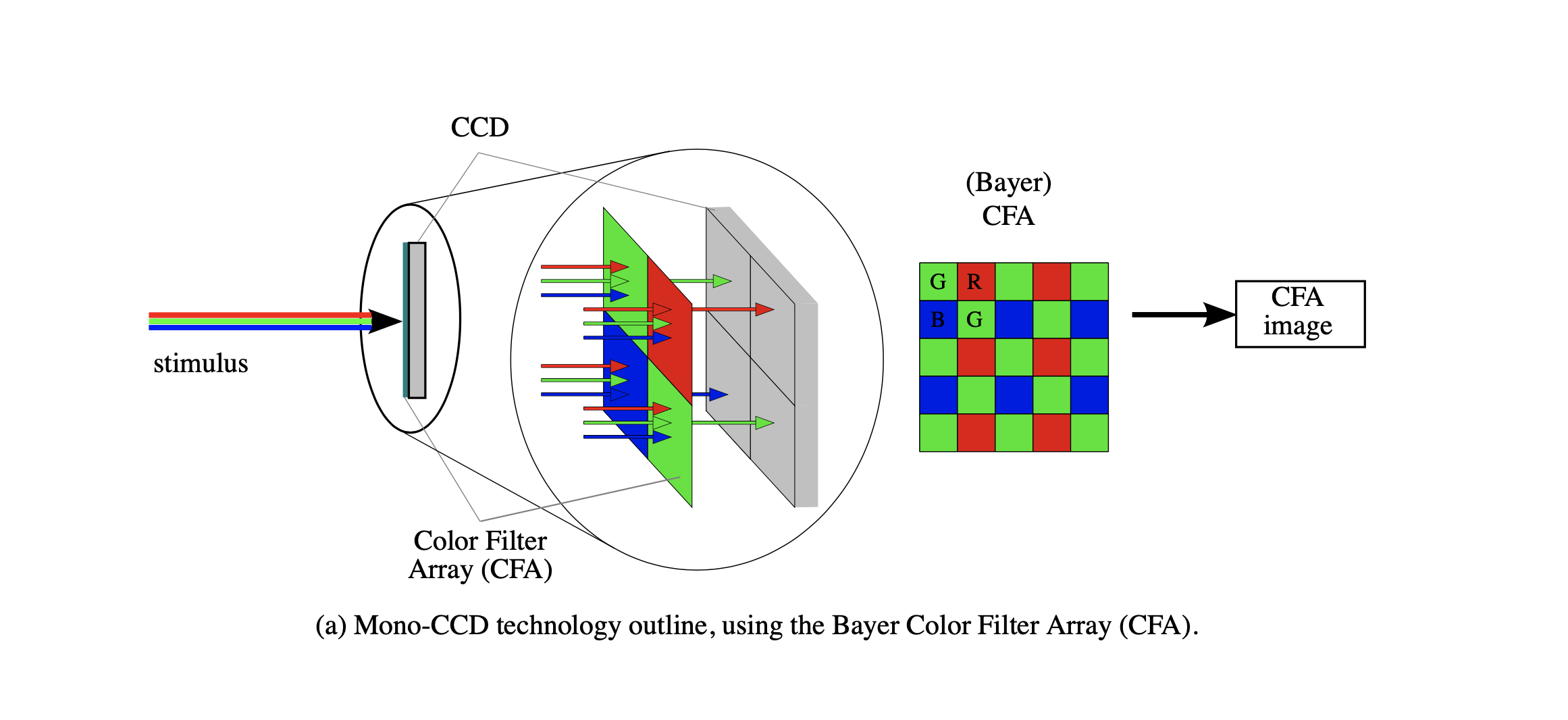 Olivier Losson, Ludovic Macaire, Yanqin Yang. Comparison of color demosaicing methods. Advances in Imaging and Electron Physics, Elsevier, 2010, 162, pp.173-265. 10.1016/S1076-5670(10)62005-8 .hal-00683233
Olivier Losson, Ludovic Macaire, Yanqin Yang. Comparison of color demosaicing methods. Advances in Imaging and Electron Physics, Elsevier, 2010, 162, pp.173-265. 10.1016/S1076-5670(10)62005-8 .hal-00683233
那么与其之后用其他软件手动debayer,何不把这一步一块用python解决?
继续发扬拿来主义,使用 colour_demosaicing 这个库,两行搞定。
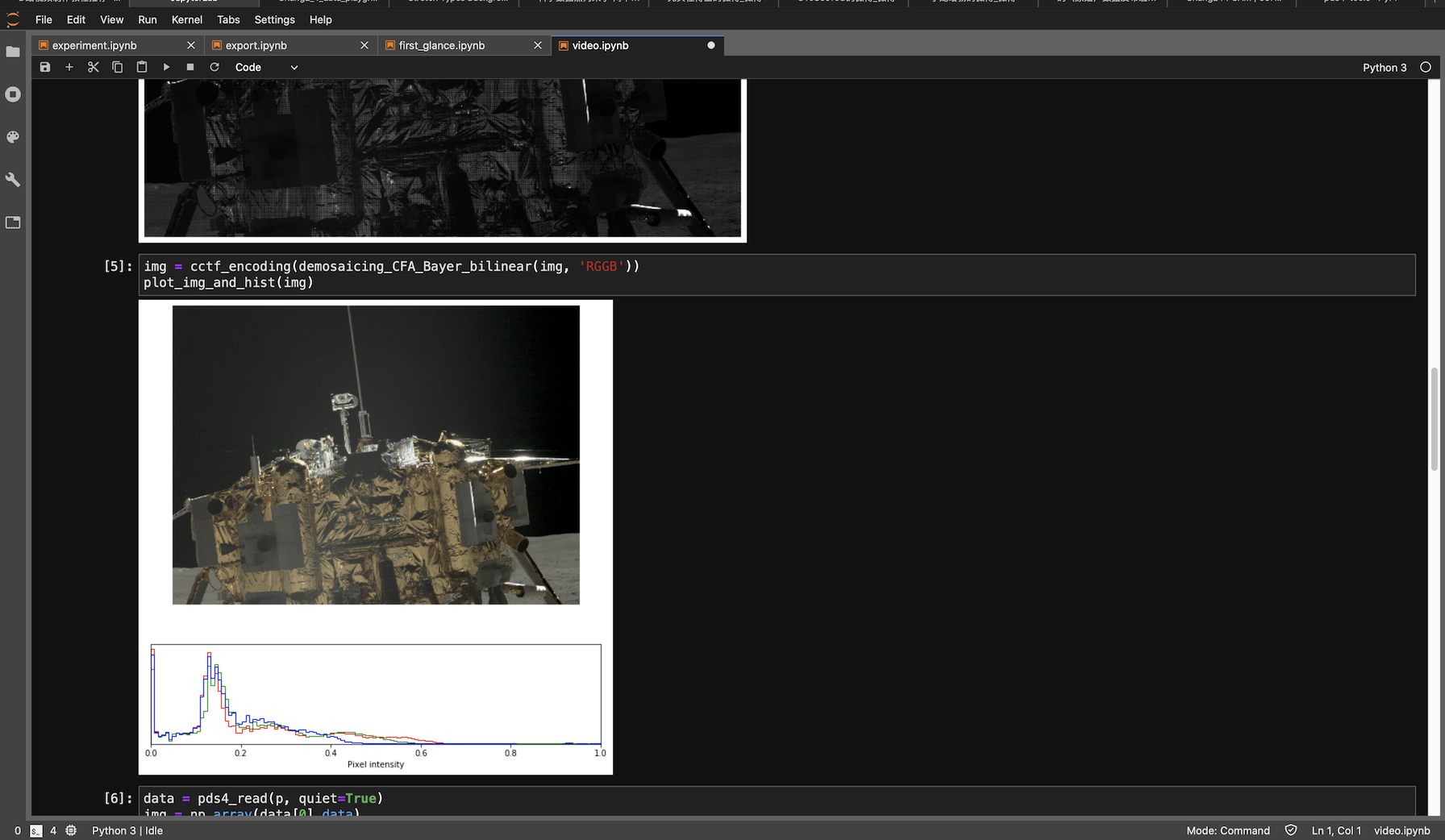 PCAM debayer 后,看上去灰蒙蒙的
PCAM debayer 后,看上去灰蒙蒙的
Debayer过后的图片有了颜色,但是曝光很奇怪,看上去灰蒙蒙的。
这是因为PCAM的原始数据是10位的,也就是从黑到白可以分成1024个灰度。而由于我们大多数人的显示器都只能显示8位的色深,也就是256个灰度,在刚才数据类型转换的过程中,我把原始数据简单粗暴地线性映射到了显示器上,也就是说10位数据的1023对应8位的255, 0对应现在的0,所有的亮度值都乘255/1023。我们看到了这样的效果并不好。
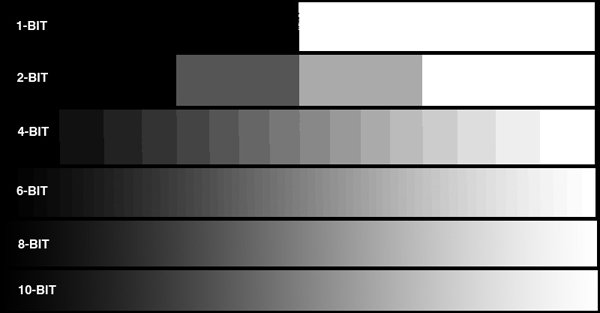 web图像,10位显示出来和8位一样. 图源:www.projectorcentral.com/All-About-Bit-Depth.htm
web图像,10位显示出来和8位一样. 图源:www.projectorcentral.com/All-About-Bit-Depth.htm
所以我们需要自己决定怎么做10位到8位的映射,方法就是直方图拉伸。
我使用的常见的linear percent stretch,先裁掉最暗和最亮的2%的像素,也就是把原图最亮的2%都定义为255,把最暗的2%都当做0,然后对中间的部分做线性拉伸。现在图片看起来是不是正常多了呢。
 PCAM 最终结果
PCAM 最终结果
有的同学也许要说了,裁掉最亮和最暗的2%,这部分的像素的信息不就丢失了吗?是的,但是没有办法,从10位到8位是一定会丢失信息,我们能做的就是尽可能的让留下来的数据价值最大化,视觉上最舒服。
至此,我们的彩色图片也算是处理完了,可以导出了。
回头来看,转换的步骤其实非常简单,实现也并不复杂,概括起来就是:
- 调库读PDS
- 调库debayer
- 小学程度乘除法
- 调库保存
- 最后再用一点代码整理文件
额这么说来好像我没干什么?其实大多数的编程工作回头来看都是这样的,真正耗费时间和精力的是摸索和踩坑的过程,对我而言这个探索的过程是非常有趣的。
除了觉得好玩,一直支持我不断完善这段程序是发布时的一条微博。
 发布时的一条微博
发布时的一条微博
当时我觉得明明是我们的数据,我们有那么多专业人员,为什么要等别人做熟肉,所以我那几天憋着这口气也想把它搞出来。
做这期视频的时候我又看到一条微博
感觉。。很荣幸能为国内的科普环境做一点微不足道的贡献吧。
闲话就说这么多,如果你有什么问题,欢迎在评论区里留言,我会尽力回复。下期我大概终于能我讲开这个号时计划讲的东西了。
附录
说了半天科学数据,你有没有想过他们到底是怎么来的呢?发布页里2B 2C这些级别是什么呢?这个附录给你讲清楚.
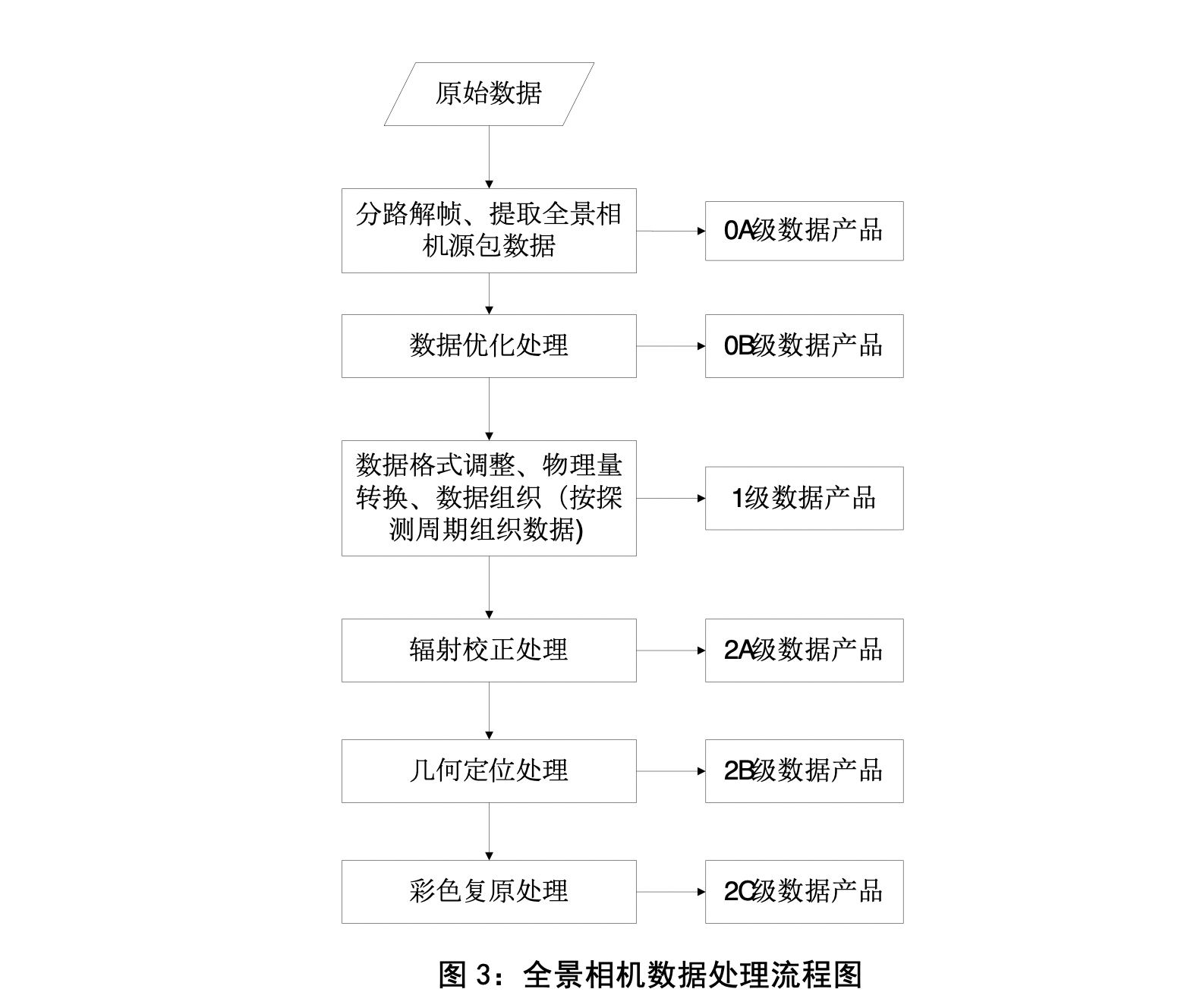
首先嫦娥玉兔拍了照片,通过鹊桥中继卫星把数据发回来。观测站的天线大锅收到流数据,经过同步、解扰、解码、多站融合纠错后得到0级数据。分类整理并加入拍摄时间、参数等元信息后我们就有了1级数据。如果这些听着像念经,没有关系,我们只需要知道1级数据近似于我们用的相机拍的raw格式数据。2级数据的获取过程其实和我们深空拍摄的后期差不太多,2A大致是经过暗场、偏置场校正的,2B再做一步平场和镜头正畸,而2C是debayer之后的。对于有些任务还有3级数据,但是我没有找到靠谱的解释,就不多说拉。